前言#
Rust is a system’s programming language that runs blazingly fast, prevents segfaults, and guarantees thread safety.
- 内存安全:Rust语言是可以保证内存安全的系统级编程语言。这是它的独特的优势。
- 并发: 在强大的内存安全特性的支持下,Rust一举解决了并发条件下的数据竞争(Data Race)问题。
- 实用:Rust摈弃了手动内存管理带来的各种不安全的弊端,同时也避免了自动垃圾回收带来的效率损失和不可控性。在绝大部分情况下,保持了“无额外性能损失”的抽象能力。
第一部分#
第1章 初识Rust#
Rust语言是一门系统编程语言,它有三大特点:运行快、防止段错误、保证线程安全。 系统级编程语言一般具有以下特点:
- 可以在资源非常受限的环境下执行;
- 运行时开销很小,非常高效;
- 很小的运行库,甚至于没有;
- 可以允许直接的内存操作。
1.1 版本和发布策略#
编译器的源码位于https://github.com/rust-lang/rust 项目中;
语言设计和相关讨论位于https://github.com/rust-lang/rfcs 项目中。
在nightly版本中使用试验性质的功能,必须手动开启feature gate。也就是说要在当前项目的入口文件中加入一条#![feature(…name…)]语句。 否则是编译不过的。等到这个功能最终被稳定了,再用新版编译器编译的时候,它会警告你这个feature gate现在是多余的了,可以去掉了。
Rust的标准库文档位于https://doc.rust-lang.org/std/ 。学会查阅标准库文档,是每个Rust使用者的必备技能之一。
1.2 安装开发环境#
- rustc.exe是编译器
- cargo.exe是包管理器
- cargo-fmt.exe和rustfmt.exe是源代码格式化工具
- rust-gdb.exe和rust-lldb.exe是调试器
- rustdoc.exe是文档生成器
- rls.exe和racer.exe是为编辑器准备的代码提示工具
- rustup.exe是管理这套工具链下载更新的工具。
RLS(Rust Language Server)是官方提供的一个标准化的编辑器增强工具。它也是开源的,项目地址在https://github.com/rust-lang-nursery/rls。它是一个单独的进程,通过进程间通信给编辑器或者集成开发环境提供一些信息,实现比较复杂的功能,比如代码自动提示、跳转到定义、显示函数签名等。
1.3 Hello World#
一般Rust源代码的后缀名使用.rs表示。源码一定要注意使用utf-8编码。
1.4 前奏#
Rust的代码从逻辑上是分crate和mod管理的。所谓crate大家可以理解为“项目”。每个crate是一个完整的编译单元,它可以生成为一个lib或者exe可执行文件。
在crate内部,则是由mod这个概念管理的,所谓mod大家可以理解为namespace。我们可以使用use语句把其他模块中的内容引入到当前模块中来。
第2章 变量和类型#
2.1 变量声明#
Rust的变量必须先声明后使用。对于局部变量,最常见的声明语法为:
1 | let variable : i32 = 100; |
从语法分析的角度来说,Rust的变量声明语法比C/C++语言的简单,局部变量声明一定是以关键字let开头,类型一定是跟在冒号:的后面。语法歧义更少,语法分析器更容易编写。
Rust的变量声明的一个重要特点是:要声明的变量前置,对它的类型描述后置。因为在变量声明语句中,最重要的是变量本身,而类型其实是个附属的额外描述,并非必不可少的部分。
let语句不光是局部变量声明语句,而且具有pattern destructure(模式解构)的功能。
Rust中声明变量缺省是“只读”的。如果我们需要让变量是可写的,那么需要使用mut关键字。let语句在此处引入了一个模式解构,我们不能把let mut视为一个组合,而应该将mut x视为一个组合。
在Rust中,一般把声明的局部变量并初始化的语句称为“变量绑定”,强调的是“绑定”的含义
每个变量必须被合理初始化之后才能被使用。使用未初始化变量这样的错误,在Rust中是不可能出现的(利用unsafe做hack除外)
类型没有“默认构造函数”,变量没有“默认值”。对于let x:i32;如果没有显式赋值,它就没有被初始化,不要想当然地以为它的值是0。
Rust里面的下划线是一个特殊的标识符,在编译器内部它是被特殊处理的。
2.1.1 变量遮蔽#
Rust允许在同一个代码块中声明同样名字的变量。如果这样做,后面声明的变量会将前面声明的变量“遮蔽”(Shadowing)起来。
这两个x代表的内存空间完全不同,类型也完全不同,它们实际上是两个不同的变量。
变量遮蔽在某些情况下非常有用,比如,我们需要在同一个函数内部把一个变量转换为另一个类型的变量,但又不想给它们起不同的名字。
在同一个函数内部,需要修改一个变量绑定的可变性。例如,我们对一个可变数组执行初始化,希望此时它是可读写的,但是初始化完成后,我们希望它是只读的。
如果一个变量是不可变的,我们也可以通过变量遮蔽创建一个新的、可变的同名变量。这个过程是符合“内存安全”的。一个“不可变绑定”依然是一个“变量”。虽然我们没办法通过这个“变量绑定”修改变量的值,但是我们重新使用“可变绑定”之后,还是有机会修改的。这样做并不会产生内存安全问题,因为我们对这块内存拥有完整的所有权,且此时没有任何其他引用指向这个变量,对这个变量的修改是完全合法的。
2.1.2 类型推导#
Rust只允许“局部变量/全局变量”实现类型推导,而函数签名等场景下是不允许的,这是故意这样设计的。这是因为局部变量只有局部的影响,全局变量必须当场初始化而函数签名具有全局性影响。
2.1.3 静态变量#
Rust中可以用static关键字声明静态变量。
用static声明的变量的生命周期是整个程序,从启动到退出。static变量的生命周期永远是’static,它占用的内存空间也不会在执行过程中回收。这也是Rust中唯一的声明全局变量的方法。
全局变量必须在声明的时候马上初始化;
全局变量的初始化必须是编译期可确定的常量,不能包括执行期才能确定的表达式、语句和函数调用;
带有mut修饰的全局变量,在使用的时候必须使用unsafe关键字
Rust不允许用户在main函数之前或者之后执行自己的代码。所以,比较复杂的static变量的初始化一般需要使用lazy方式,在第一次使用的时候初始化。在Rust中,如果用户需要使用比较复杂的全局变量初始化,推荐使用lazy_static库。
2.1.4 常量#
使用const声明的是常量,而不是变量。因此一定不允许使用mut关键字修饰这个变量绑定,这是语法错误。
编译器并不一定会给const常量分配内存空间,在编译过程中,它很可能会被内联优化。因此,用户千万不要用hack的方式,通过unsafe代码去修改常量的值,这么做是没有意义的。以const声明一个常量,也不具备类似let语句的模式匹配功能。
2.2 基本数据类型#
- bool
- char: 描述任意一个unicode字符,因此它占据的内存空间不是1个字节,而是4个字节。对于ASCII字符其实只需占用一个字节的空间,因此Rust提供了单字节字符字面量来表示ASCII字符。我们可以使用一个字母b在字符或者字符串前面,代表这个字面量存储在u8类型数组中,这样占用空间比char型数组要小一些。
- 整形类型:
- isize和usize类型。它们占据的空间是不定的,与指针占据的空间一致,与所在的平台相关。如果是32位系统上,则是32位大小;如果是64位系统上,则是64位大小。
- 在C++中与它们相对应的类似类型是int_ptr和uint_ptr。在语言标准中规定好各个类型的大小,让编译器针对不同平台做适配,生成不同的代码,是更合理的选择。
- 在所有的数字字面量中,可以在任意地方添加任意的下划线,以方便阅读
let var1 = 0x_ff_u8。字面量后面可以跟后缀,可代表该数字的具体类型,从而省略掉显示类型标记。 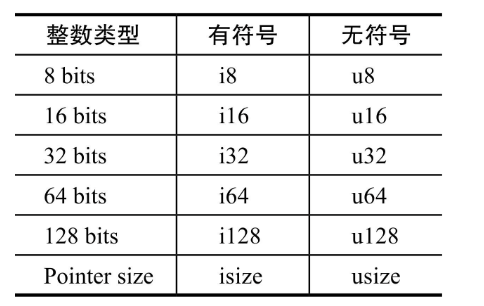
- 整数溢出:默认情况下,在debug模式下编译器会自动插入整数溢出检查,一旦发生溢出,则会引发panic;在release模式下,不检查整数溢出,而是采用自动舍弃高位的方式
- 浮点类型:
- 在标准库中,有一个std::num::FpCategory枚举,表示了浮点数可能的状态。
Nan Infinite Zero Subnormal Normal - 在IEEE 754标准中,规定了浮点数的二进制表达方式:x =(-1)^s * (1 + M) *2^e。其中s是符号位,M是尾数,e是指数。尾数M是一个[0, 1)范围内的二进制表示的小数。
- 数值就小到了无法在32bit范围内合理表达的程度,最终收敛到了0,在后面表示非常小的数值的时候,浮点数就已经进入了Subnormal状态。
- Nan != Nan 因为NaN的存在,浮点数是不具备“全序关系”(total order)的。
- 在标准库中,有一个std::num::FpCategory枚举,表示了浮点数可能的状态。
- 指针类型
- 类型转换:在Rust中使用As作为类型转换


2.3 复合数据类型#
Tuple: tuple指的是“元组”类型,它通过圆括号包含一组表达式构成。tuple内的元素没有名字。tuple是把几个类型组合到一起的最简单的方式。
1
2
3
4
5
6let p = (1i32, 2i32);
let x = p.0;
let y = p.1;
let empty:() = ();元组内部也可以一个元素都没有。这个类型单独有一个名字,叫unit(单元类型).unit类型是Rust中最简单的类型之一,也是占用空间最小的类型之一。空元组和空结构体struct Foo;一样,都是占用0内存空间。
Struct:
1
2
3
4
5
6
7
8
9
10
11
12struct Point {
x:i32,
y:i32,
}
fn main() {
let x= 10;
let y =20;
let p = Point{x, y};
let p2 = Point{x:0, y:0};
println!("Point is", p.x, p.y);
}Rust设计了一个语法糖,允许用一种简化的语法赋值使用另外一个struct的部分成员。
1
2
3
4
5
6
7
8
9
10
11struct Point3d {
x:i32,
y:i32,
z:i32,
}
fn default() -> Point3d {
Point3d {x:0, y:0, z:0}
}
let orign = Point3d {x :5, ..default()};
let point = Point3d {y :1, ..orign};Rust有一种数据类型叫作tuple struct,它就像是tuple和struct的混合。区别在于,tuple struct有名字,而它们的成员没有名字
第3章 语句和表达式#
3.1 语句#
一个表达式总是会产生一个值,因此它必然有类型;语句不产生值,它的类型永远是()。
3.2 表达式#
Rust表达式又可以分为“左值”(lvalue)和“右值”(rvalue)两类。所谓左值,意思是这个表达式可以表达一个内存地址。因此,它们可以放到赋值运算符左边使用。其他的都是右值。
3.2.1 运算表达式#
比较运算符的两边必须是同类型的,并满足PartialEq约束。比较表达式的类型是bool。另外,Rust禁止连续比较
所谓逻辑运算符短路的意思是:
- 对于表达式A&&B,如果A的值是false,那么B就不会执行求值,直接返回false.
- 对于表达式A||B,如果A的值是true,那么B就不会执行求值,直接返回true。
- 而“按位与”、“按位或”在任何时候都会先执行左边的表达式,再执行右边的表达式,不会省略。
3.2.2 赋值表达式#
赋值表达式具有“副作用”:当它执行的时候,会把右边表达式的值“复制或者移动”(copy or move)到左边的表达式中。
赋值号左右两边表达式的类型必须一致,否则是编译错误。
赋值表达式也有对应的类型和值。这里不是说赋值表达式左操作数或右操作数的类型和值,而是说整个表达式的类型和值。Rust规定,赋值表达式的类型为unit,即空的tuple ()。Rust这么设计是有原因的,比如说可以防止连续赋值。如果你有x: i32、y: i32以及z: i32,那么表达式z = y = x会发生编译错误。因为变量z的类型是i32但是却用()对它初始化了,编译器是不允许通过的。
Rust不支持++、–运算符,请使用+= 1、-= 1替代
3.2.3 语句块表达式#
在Rust中,语句块也可以是表达式的一部分。语句和表达式的区分方式是后面带不带分号(;)。
例如:
1 | fn my_func() -> i32 |
最后一条表达式没有加分号,因此整个语句块的类型就变成了i32,刚好与函数的返回类型匹配。这种写法与return 100;语句的效果是一样的,相较于return语句来说没有什么区别,但是更加简洁。特别是用在后面讲到的闭包closure中,这样写就方便轻量得多。
3.3 if-else#
规定if和else后面必须有大括号,可读性会好很多。
条件表达式并未强制要求用小括号包起来;如果加上小括号,编译器反而会认为这是一个多余的小括号,给出警告
1 | if ... { |
if-else结构还可以当表达式使用,因此在Rust中,没有必要专门设计像C/C++那样的三元运算符(? :)语法,因为通过现有的设计可以轻松实现同样的功能:
1 | let x:i32 = if condition {1} else {10}; |
如果使用if-else作为表达式,那么一定要注意,if分支和else分支的类型必须一致,否则就不能构成一个合法的表达式,会出现编译错误。如果else分支省略掉了,那么编译器会认为else分支的类型默认为()。
1 | fn invalid_expr(cond :bool) -> i32 { |
如果此处编译器不报错,放任程序编译通过,那么在执行到else分支的时候,就只能返回一个未初始化的值,这在Rust中是不允许的。
3.3.1 loop#
在Rust中,使用loop表示一个无限死循环。另外,break语句和continue语句还可以在多重循环中选择跳出到哪一层的循环。
1 | fn test5() |
在loop内部break的后面可以跟一个表达式,这个表达式就是最终的loop表达式的值。如果一个loop永远不返回,那么它的类型就是“发散类型”。
1 | fn main() |
编译器可以判断出v的类型是发散类型,而后面的打印语句是永远不会执行的死代码。
3.3.2 while#
为什么Rust专门设计了一个死循环,loop语句难道不是完全多余的吗?
相比于其他的许多语言,Rust语言要做更多的静态分析。loop和while true语句在运行时没有什么区别,它们主要是会影响编译器内部的静态分析结果。
3.3.3 for#
Rust中的for循环实际上是许多其他语言中的for-each循环。
1 | let array = &[1,2,3,4,5]; |
第4章 函数#
4.1 简介#
函数也可以不写返回类型,在这种情况下,编译器会认为返回类型是unit ()
函数可以当成头等公民(first class value)被复制到一个值中,这个值可以像函数一样被调用。
每一个函数都具有自己单独的类型,但是这个类型可以自动转换到fn类型。
即使两个函数有同样的参数类型和同样的返回值类型,但它们是不同类型,如果直接赋值的话就会报错报错了。修复方案是让func的类型为通用的fn类型即可:
1 | // 使用as类型转换 |
Rust的函数体内也允许定义其他item,包括静态变量、常量、函数、trait、类型、模块等。当你需要一些item仅在此函数内有用的时候,可以把它们直接定义到函数体内,以避免污染外部的命名空间。
4.2 发散函数#
Rust支持一种特殊的发散函数(Diverging functions),它的返回类型是感叹号!。如果一个函数根本就不能正常返回
1 | fn diverges() -> ! { |
因为panic!会直接导致栈展开,所以这个函数调用后面的代码都不会继续执行,它的返回类型就是一个特殊的!符号,这种函数也叫作发散函数。发散类型的最大特点就是,它可以被转换为任意一个类型。
在Rust中,有以下这些情况永远不会返回,它们的类型就是!:
- panic!以及基于它实现的各种函数/宏,比如unimplemented! 、unreachable!;
- 死循环loop {};
- 进程退出函数std::process::exit以及类似的libc中的exec一类函数。
4.3 main函数#
传递参数和返回状态码都由单独的API来完成,如果要读取环境变量,可以用std::env::var()以及std::env::vars()函数获得。
1 | fn main() { |
4.4 const fn#
函数可以用const关键字修饰,这样的函数可以在编译阶段被编译器执行,返回值也被视为编译期常量。
第5章 trait#
trait更多关注于行为的抽象,而不持有数据。- 类通常是数据和行为的封装体,并且具有实例化能力。
- 在 Rust 中,没有类的概念。Rust 使用结构体(
struct)来封装数据,而行为则通过实现trait来定义。
5.1 成员方法#
所有的trait中都有一个隐藏的类型Self(大写S),代表当前这个实现了此trait的具体类型。
trait中定义的函数,也可以称作关联函数(associated function)。
函数的第一个参数如果是Self相关的类型,且命名为self(小写s),这个参数可以被称为“receiver”(接收者)。具有receiver参数的函数,我们称为“方法”(method),可以通过变量实例使用小数点来调用。
没有receiver参数的函数,我们称为“静态函数”(static function),可以通过类型加双冒号::的方式来调用。
Rust中Self(大写S)和self(小写s)都是关键字,大写S的是类型名,小写s的是变量名。
另外,针对一个类型,我们可以直接对它impl来增加成员方法,无须trait名字。我们可以把这段代码看作是为Circle类型impl了一个匿名的trait。用这种方式定义的方法叫作这个类型的“内在方法”(inherent methods)。
5.2 静态方法#
没有receiver参数的方法(第一个参数不是self参数的方法)称作“静态方法”。静态方法可以通过Type::FunctionName()的方式调用。
需要注意的是,即便我们的第一个参数是Self相关类型,只要变量名字不是self,就不能使用小数点的语法调用函数。
5.3 扩展方法#
我们还可以利用trait给其他的类型添加成员方法,哪怕这个类型不是我们自己写的。
在声明trait和impl trait的时候,Rust规定了一个Coherence Rule(一致性规则)或称为Orphan Rule(孤儿规则):impl块要么与trait的声明在同一个的crate中,要么与类型的声明在同一个crate中。
如果trait来自于外部crate,而且类型也来自于外部crate,编译器不允许你为这个类型impl这个trait。
trait本身既不是具体类型,也不是指针类型,它只是定义了针对类型的、抽象的“约束”。不同的类型可以实现同一个trait,满足同一个trait的类型可能具有不同的大小。因此,trait在编译阶段没有固定大小,目前我们不能直接使用trait作为实例变量、参数、返回值。
5.4 完整函数调用语法#
这个语法可以允许使用类似的写法精确调用任何方法,包括成员方法和静态方法。其他一切函数调用语法都是它的某种简略形式。它的具体写法为<T as TraitName>::item。
1 | trait Cook { |
需要注意的是,通过小数点语法调用方法调用,有一个“隐藏着”的“取引用”步骤。虽然我们看起来源代码长的是这个样子me.start(),但是大家心里要清楚,真正传递给start()方法的参数是&me而不是me,这一步是编译器自动帮我们做的。
5.5 trait的约束和集成#
Rust可以对泛型有约束,比如只要实现了一个Debug trait的结构体都可以传入到这个泛型结构里面。泛型约束既是对实现部分的约束,也是对调用部分的约束。
1 | use std::fmt::Debug; |
trait允许继承。
1 | trait Base {...} |
这表示Derived trait继承了Base trait。它表达的意思是,满足Derived的类型,必然也满足Base trait。所以,我们在针对一个具体类型impl Derived的时候,编译器也会要求我们同时impl Base。
5.6 derive#
Rust里面为类型impl某些trait的时候,逻辑是非常机械化的。为许多类型重复而单调地impl某些trait,是非常枯燥的事情。为此,Rust提供了一个特殊的attribute,它可以帮我们自动impl某些trait。它的语法是,在你希望impl trait的类型前面写#[derive(…)],括号里面是你希望impl的trait的名字。这样写了之后,编译器就帮你自动加上了impl块。
1 |
|
支持自动化derive的trait有以下:
1 | Debug Clone Copy Hash RustcEncodable RustcDecodable PartialEq Eq ParialOrd Ord Default FromPrimitive Send Sync |
5.7 trait 别名#
1 | pub trait Service { |
5.8 常见的标准库trait#
5.8.1 Display 和 Debug#
只有实现了Display trait的类型,才能用{}格式控制打印出来;只有实现了Debug trait的类型,才能用{:? } {:#? }格式控制打印出来。
5.8.2 PartialOrd和Ord#
因为NaN的存在,浮点数是不具备“total order(全序关系)”的。在这里,我们详细讨论一下什么是全序、什么是偏序。Rust标准库中有如下解释。对于集合X中的元素a, b, c,
- 如果a < b则一定有! (a > b);反之,若a > b,则一定有!(a < b),称为反对称性。
- 如果a < b且b < c则a < c,称为传递性。
- 对于X中的所有元素,都存在a < b或a > b或者a == b,三者必居其一,称为完全性。
如果集合X中的元素只具备上述前两条特征,则称X是“偏序”。同时具备以上所有特征,则称X是“全序”。因为浮点数中特殊的值NaN不满足完全性。
只有Ord trait里面的cmp函数才能返回一个确定的Ordering。f32和f64类型都只实现了PartialOrd,而没有实现Ord。
因此,对浮点数数组求最大值是会报错的,因为Nan的存在,不能求出最大值。
5.8.3 Sized#
不定长类型在使用的时候有一些限制,比如不能用它作为函数的返回类型,而必须将这个类型藏到指针背后才可以。
Rust中对于动态大小类型专门有一个名词Dynamic Sized Type。我们后面将会看到的[T],str以及dyn Trait都是DST。
5.8.4 Default#
所以Rust里面推荐使用普通的静态函数作为类型的“构造器”。比如,常见的标准库中提供的字符串类型String
第6章 数组和字符串#
6.1 数组#
数组是一个容器,它在一块连续空间内存中,存储了一系列的同样类型的数据。只有元素类型和元素个数都完全相同,这两个数组才是同类型的。只有元素类型和元素个数都完全相同,这两个数组才是同类型的。
1 | let xs:[i32;5] = [1,2,3,4,5] |
把数组xs作为参数传给一个函数,这个数组并不会退化成一个指针。而是会将这个数组完整复制进这个函数。函数体内对数组的改动不会影响到外面的数组。
对数组内部元素的访问,可以使用中括号索引的方式。Rust支持usize类型的索引的数组,索引从0开始计数。
既然[T; n]是一个合法的类型,那么它的元素T当然也可以是数组类型,因此[[T; m]; n]类型自然也是合法类型。
对数组取借用borrow操作,可以生成一个“数组切片”(Slice)。数组切片对数组没有“所有权”,我们可以把数组切片看作专门用于指向数组的指针,是对数组的另外一个“视图”。
DST和胖指针#
Slice与普通的指针是不同的,它有一个非常形象的名字:胖指针(fat pointer)。与这个概念相对应的概念是“动态大小类型”(Dynamic Sized Type, DST)。所谓的DST指的是编译阶段无法确定占用空间大小的类型。为了安全性,指向DST的指针一般是胖指针。胖指针内部的数据既包含了指向源数组的地址,又包含了该切片的长度。
对于DST类型,Rust有如下限制:
- 只能通过指针来间接创建和操作DST类型,&[T]Box<[T]>可以,[T]不可以;
- 局部变量和函数参数的类型不能是DST类型,因为局部变量和函数参数必须在编译阶段知道它的大小因为目前unsized rvalue功能还没有实现;
- enum中不能包含DST类型,struct中只有最后一个元素可以是DST,其他地方不行,如果包含有DST类型,那么这个结构体也就成了DST类型。
这一设计的好处有:
- 首先,DST类型虽然有一些限制条件,但我们依然可以把它当成合法的类型看待,比如,可以为这样的类型实现trait、添加方法、用在泛型参数中等;
- 胖指针的设计,避免了数组类型作为参数传递时自动退化为裸指针类型,丢失了长度信息的问题,保证了类型安全;
- 这一设计依然保持了与“所有权”“生命周期”等概念相容的特点。
Range#
Rust中的Range代表一个“区间”,一个“范围”,它有内置的语法支持,就是两个小数点..
在begin..end这个语法中,前面是闭区间,后面是开区间。
在Rust中,还有其他的几种Range,包括
- std::ops::RangeFrom代表只有起始没有结束的范围,语法为start..,含义是[start, +∞);
- std::ops::RangeTo代表没有起始只有结束的范围,语法为..end,对有符号数的含义是(-∞, end),对无符号数的含义是[0, end);
- std::ops::RangeFull代表没有上下限制的范围,语法为..,对有符号数的含义是(-∞, +∞),对无符号数的含义是[0, +∞)。
虽然左闭右开区间是最常用的写法,然而,在有些情况下,这种语法不足以处理边界问题。比如,我们希望产生一个i32类型的从0到i32::MAX的范围,就无法表示。因为按语法,我们应该写0..(i32::MAX + 1),然而(i32::MAX+1)已经溢出了。所以,Rust还提供了一种左闭右闭区间的语法,它使用这种语法来表示..=
边界检查#
在Rust中,“索引”操作也是一个通用的运算符,是可以自行扩展的。如果希望某个类型可以执行“索引”读操作,就需要该类型实现std::ops::Index trait,如果希望某个类型可以执行“索引”写操作,就需要该类型实现std::ops::IndexMut trait。
6.2 字符串#
Rust的字符串显得有点复杂,主要是跟所有权有关。Rust的字符串涉及两种类型,一种是&str,另外一种是String。
6.2.1 &str#
str是Rust的内置类型。&str是对str的借用。Rust的字符串内部默认是使用utf-8编码格式的。
Rust里面的字符串不能视为char类型的数组,而更接近u8类型的数组。
就是不能支持O(1)时间复杂度的索引操作。如果我们要找一个字符串s内部的第n个字符,不能直接通过s[n]得到,这一点跟其他许多语言不一样。在Rust中,这样的需求可以通过下面的语句实现:
1 | s.chars().nth(n) |
它的时间复杂度是O(n),因为utf-8是变长编码,如果我们不从头开始过一遍,根本不知道第n个字符的地址在什么地方。但是,综合来看,选择utf-8作为内部默认编码格式是缺陷最少的一种方式了。相比其他的编码格式,它有相当多的优点。比如:它是大小端无关的,它跟ASCII码兼容,它是互联网上的首选编码,等等。
6.2.2 String#
接下来讲String类型。它跟&str类型的主要区别是,它有管理内存空间的权力。
&str类型是对一块字符串区间的借用,它对所指向的内存空间没有所有权,哪怕&mut str也一样。
String类型在堆上动态申请了一块内存空间,它有权对这块内存空间进行扩容
第7章 模式结构#
模式结构的意思是:把原来的结构肢解为单独的、局部的、原始的部分 。
构造和解构遵循类似的语法,我们怎么把一个数据结构组合起来的,我们就怎么把它拆解开来。
1 | let tuple = (1i32, false, 3f32); |
7.2 match#
当一个类型有多种取值可能性的时候,特别适合使用match表达式。
如果我们进行匹配的值同时符合好几条分支,那么总会执行第一条匹配成功的分支,忽略其他分支。
7.2.1 exhaustive#
因为Rust要求match需要对所有情况做完整的、无遗漏的匹配,如果漏掉了某些情况,是不能编译通过的。exhaustive意思是无遗漏的、穷尽的、彻底的、全面的。exhaustive是Rust模式匹配的重要特点。
有些时候我们不想把每种情况一一列出,可以用一个下划线来表达“除了列出来的那些之外的其他情况”
7.2.2 下划线#
下划线还能用在模式匹配的各种地方,用来表示一个占位符,虽然匹配到了但是忽略它的值的情况
下划线在Rust里面用处很多,比如:在match表达式中表示“其他分支”,在模式中作为占位符,还可以在类型中做占位符,在整数和小数字面量中做连接符,等等。
除了下划线可以在模式中作为“占位符”,还有两个点..也可以在模式中作为“占位符”使用。下划线表示省略一个元素,两个点可以表示省略多个元素。
7.2.3 match也是表达式#
match表达式的每个分支可以是表达式,它们要么用大括号包起来,要么用逗号分开。每个分支都必须具备同样的类型。
我们还可以使用范围作为匹配条件,使用..表示一个前闭后开区间范围,使用..=表示一个闭区间范围
1 | let x = 'X'; |
7.2.4 guards#
可以使用if作为“匹配看守”(match guards)。当匹配成功且符合if条件,才执行后面的语句。
1 | enum OptionalInt { |
7.2.5 变量绑定#
可以使用@符号绑定变量。@符号前面是新声明的变量,后面是需要匹配的模式:
1 | let x = 1; |
7.2.6 ref和mut#
如果我们需要绑定的是被匹配对象的引用,则可以使用ref关键字。之所以在某些时候需要使用ref,是因为模式匹配的时候有可能发生变量的所有权转移,使用ref就是为了避免出现所有权转移。ref是“模式”的一部分,它只能出现在赋值号左边,而&符号是借用运算符,是表达式的一部分,它只能出现在赋值号右边。
1 | let x = 5_i32; |
以上两处的mut含义是不同的。第1处mut,代表这个变量x本身可变,因此它能够重新绑定到另外一个变量上去,具体到这个示例来说,就是指针的指向可以变化。第2处mut,修饰的是指针,代表这个指针对于所指向的内存具有修改能力,因此我们可以用*x = 1;这样的语句,改变它所指向的内存的值。
7.3 if-let和while-let#
Rust不仅能在match表达式中执行“模式解构”,在let语句中,也可以应用同样的模式。Rust还提供了if-let语法糖。它的语法为if let PATTERN =EXPRESSION { BODY }。后面可以跟一个可选的else分支。
第8章 类型系统#
8.1 代数类型系统#
一个类型所有取值的可能性叫作这个类型的“基数”(cardinality)。
最简单的类型unit ()的基数就是1,它可能的取值范围只能是()。再比如说,bool类型的基数就是2,可能的取值范围有两个,分别是true和false。对于i32类型,它的取值范围是232,我们用Cardinality(i32)来代表i32的基数。
我们把多个类型组合到一起形成新的复合类型,这个新的类型就会有新的基数。如果两个类型的基数是一样的,那么我们可以说它们携带的信息量其实是一样的,我们也可以说它们是“同构”的。
对于数组类型,可以对应为每个成员类型都相同的tuple类型(或者struct是一样的)。用数学公式类比,则比较像乘方运算。
Rust中的enum类型就相当于代数中的“求和”运算。比如,某个类型可以代表“东南西北”四个方向,
空的enum可以类比为数字0; unit类型或者空结构体可以类比为数字1; enum类型可以类比为代数运算中的求和;tuple、struct可以类比为代数运算中的求积;数组可以类比为代数运算中的乘方。
加法具有交换率,同理,enum中的成员交换位置,也不会影响它的表达能力;乘法具有交换率,同理,struct中的成员交换位置,也不影响它的表达能力。
8.2 Nerver Type#
像unit类型和没有成员的空struct类型,都可以类比为代数中的数字1。这样的类型在内存中实际需要占用的空间为bits_of(()) = log2(1) = 0。也就是说,这样的类型实际上是0大小的类型。
这样的类型在Rust类型系统中的名字叫作never type,它们有一些属性是其他类型不具备的:
- 它们在运行时根本不可能存在,因为根本没有什么语法可以构造出这样的变量;
- Cardinality(Never) = 0;
- 考虑它需要占用的内存空间bits_of(Never) = log2(0) = -∞,也就是说逻辑上是不可能存在的东西;
- 处理这种类型的代码,根本不可能执行;
- 返回这种类型的代码,根本不可能返回;
- 它们可以被转换为任意类型。
8.3 Option#
利用类型系统(ADT)将空指针和非空指针区别开来,分别赋予它们不同的操作权限,禁止针对空指针执行解引用操作。编译器和静态检查工具不可能知道一个变量在运行期的“值”,但是可以检查所有变量所属的“类型”,来判断它是否符合了类型系统的各种约定。如果我们把null从一个“值”上升为一个“类型”,那么静态检查就可以发挥其功能了。实际上早就已经有了这样的设计,叫作Option Type,并在scala、haskell、Ocaml、F#等许多程序设计语言中存在了许多年。
Option类型不仅在表达能力上非常优秀,而且运行开销也非常小。在这里我们还可以再次看到“零性能损失的抽象”能力
- 如果从逻辑上说,我们需要一个变量确实是可空的,那么就应该显式标明其类型为Option
,否则应该直接声明为T类型。从类型系统的角度来说,这二者有本质区别,切不可混为一谈。 - 不要轻易使用unwrap方法。这个方法可能会导致程序发生panic。对于小工具来说无所谓,在正式项目中,最好是使用lint工具强制禁止调用这个方法。
- 相对于裸指针,使用Option包装的指针类型的执行效率不会降低,这是“零开销抽象”。
- 不必担心这样的设计会导致大量的match语句,使得程序可读性变差。因为Option
类型有许多方便的成员函数,再配合上闭包功能,实际上在表达能力和可读性上要更胜一筹。