读书笔记:数据库查询优化器的艺术:原理解析与SQL性能优化#
第一篇 查询优化技术#
一、数据库的查询优化#
查询优化旨在以最小 I/O、CPU 及网络代价获得结果;核心措施包括查询重用(结果与计划缓存)、等价重写、物理算法及连接顺序的规则-代价混合寻优,并行执行、分布式传输策略与架构差异(SD vs SN)。多表连接因组合爆炸,常借启发式、动态规划、贪婪和遗传算法缩减搜索;并行度取决于资源与算子粒度,在分布式场景则需将网络传输代价纳入模型,以找到全局最优计划。
查询优化的追求目标,就是在数据库查询优化引擎生成一个执行策略的过程中,尽量使查询的总开销(总开销通常包括IO、CPU、网络传输等)达到最小。
查询优化技术主要包括查询重用技术、查询重写规则、查询算法优化技术、并行查询优化技术、分布式查询优化技术及其他方面(如框架结构);
1.1 查询重用#
查询结果的重用:存放SQL文本到最后结果集的映射。节约了查询计划生成时间和查询执行过程的时间。
点击展开/ 收起
结果集缓存通常只对 **确定性、只读** 的 `SELECT` 生效,并在**源表 DDL/DML 或 TTL** 触发失效。内置结果集缓存的数据库#
Oracle (SQL Result Cache)
- 两级缓存:SGA 级别的 Server Result Cache 与客户端级 Client Result Cache。
RESULT_CACHE MODE可设为MANUAL/FORCE;也可在查询上加/*+ RESULT_CACHE */Hint。- 默认按 表块 SCN 自动失效。 (xbdba.com)
MySQL (Query Cache,已在 8.0 移除)
- ≤ 5.7 版本以 KV 方式保存 SQL 文本 → 结果集,并在涉及表有写操作时全表失效。
- 高并发下全局互斥锁成为瓶颈,官方在 8.0 彻底删除该特性。 (dev.mysql.com, mysql.taobao.org)
Amazon Redshift (Result Cache)
- Leader 节点内存持有缓存;会话级参数
enable_result_cache_for_session控制使用。 - 命中后完全跳过计算,典型查询耗时可从数秒降到毫秒级。 (docs.aws.amazon.com, docs.aws.amazon.com)
Snowflake (Persisted Query Results)
- 24 h TTL,每被命中一次自动续期,最长 31 天。
- 可通过
USE_CACHED_RESULT = FALSE关闭;也可利用RESULT_SCAN(<query_id>)对缓存结果做二次查询。 (docs.snowflake.com, docs.snowflake.com)
Google BigQuery (Cached Results)
- 对交互式与批处理查询统一缓存 约 24 h,大小上限 10 GB(压缩后)。
--use_cache=false或界面复选框可禁用。- 缓存命中不计扫描字节费用,只占并发额度。 (cloud.google.com, cloud.google.com)
ClickHouse (Query Result Cache,23.3+)
- 通过
query_result_cache_max_size、query_cache_squash_partial_results等参数启用; - 支持分块、分片环境下的局部失效。 (clickhouse.com)
“外挂”式方案#
PostgreSQL
- Pgpool-II “In-Memory Query Cache”
- 命中规则同 Result Cache,表有写操作即失效;无需改应用 SQL。 (pgpool.net, pgpool.net)
DuckDB
- 嵌入式列存,可把上次结果写入本地 DuckDB 文件或 ATTACH 的 Delta 表,供后续 SQL 直接读取,相当于手动结果缓存。 (linkedin.com, duckdb.org)
如果你的查询满足“读多写少 + SQL 重复度高 + 结果集相对稳定”,优先考虑启用 数据库级结果集缓存(Oracle、Snowflake、Redshift、BigQuery、ClickHouse);若所用数据库未内建,可在 代理层(Pgpool-II)或嵌入式分析库(DuckDB) 上补充,实现 SQL→完整结果 的直通复用,从而把解析、优化乃至执行成本降为 0。
查询计划的重用:查询计划的重用技术减少了查询计划生成的时间和资源消耗。
1.2 查询重写规则#
查询重写是查询语句的一种等价转换,关系代数的等价变换规则对查询重写提供了理论上的支持。主要目标是:
- 将查询转换为等价的、效率更高的形式,例如消除重复条件、转换为效率高的谓词等;
- 尽量将查询重写为等价、简单且不受表顺序限制的形式,为物理查询优化阶段提供更多的选择,如视图的重写、子查询的合并转换等。
查询重写技术优化思路主要包括:
- 将过程性查询转换为描述性的查询,如视图重写。-
- 将复杂的查询(如嵌套子查询、外连接、嵌套连接)尽可能转换为多表连接查询。
- 将效率低的谓词转换为等价的效率高的谓词(如等价谓词重写)。
- 利用等式和不等式的性质,简化WHERE、HAVING和ON条件。
1.3 查询算法优化#
从一个查询计划看,涉及到的树中的关系结点包括:
- 单表结点。考虑单表的数据获取方式,是直接通过IO获得数据,还是通过索引获取数据,或者是通过索引定位数据的位置后再经过IO到数据块中获取数据。这是一个从物理存储到内存解析成逻辑字段的过程。
- 两表结点。考虑两表以何种方式连接、代价有多大、连接路径有哪些等。不同的连接算法导致的连接效率不同,如数据多时可使用Hash连接,外表数据量小且内表数据量大时可使用嵌套连接,数据如果有序可使用归并连接或先排序后使用归并连接等。
- 多表中间结点。考虑多表连接顺序如何构成代价最少的“执行计划”。决定是AB先连接还是BC先连接,这是一个比较花费大小的运算。如果判断的连接方式太多,也会导致效率问题。
生成最好的查询计划的策略通常有两个:
基于规则优化。
根据经验或一些已经探知或被证明有效的方式,用这些规则化简查询计划生成过程中符合可被化简的操作,使用启发式规则排除一些明显不好的存取路径。基于规则优化具有操作简单且能快速确定连接方式的优点,但这种方法只是排除了一部分不好的可能,所以得到的结果未必是最好的;
基于代价优化。
根据一个代价评估模型,在生成查询计划的过程中,计算每条存取路径(存取路径主要包括上述3个“关系结点”)的花费,然后选择代价最小的作为子路径,这样直至所有表连接完毕得到一个完整的路径。主流数据库都采用了基于代价策略进行优化的技术。基于代价优化是对各种可能的情况进行量化比较,从而可以得到花费最小的情况,但如果组合情况比较多则花费的判断时间就会很多;查询优化器的实现,多是两种优化策略组合使用
多表连接是最难的,因为多个表连接时可以有多种不同的连接次序,所以查询的执行计划的数目会随着该查询包含的表个数呈指数级增长,将导致搜索空间极度膨胀,搜索花费最小的查询计划就需要耗费巨大的时间和资源,常用的算法有:
- SYSTEM-R算法。近乎穷举的搜索算法。
- 启发式搜索算法。基于规则(基于“启发式规则”抛弃不好的存取路径挑选好的)。
- 贪婪算法。根据某种优化方式,以当前情况为基础做出最优选择,认为每次搜索过的局部存取路径是最优的,然后继续探索与其他表的连接路径。
- 动态规划算法。
- 遗传算法。一种启发式的优化算法,抛弃了传统的搜索方式,模拟自然界生物进化过程,基于自然群体遗传演化机制,采用人工进化的方式对目标空间进行随机化搜索。
1.4 并行查询优化#
一个查询能否并行执行,取决于以下因素:
- 系统中的可用资源(如内存、高速缓存中的数据量等)。
- CPU的数目。
- 运算中的特定代数运算符。
如A、B、C、D4个表进行连接,每个表的单表扫描可以并行进行;在生成4个表连接的查询计划过程中,可选择A和B连接的同时C和D进行连接,这样连接操作能并行运行。
在同一个SQL内,查询并行可以分为以下两种:- 操作内并行。将同一操作如单表扫描操作、两表连接操作、排序操作等分解成多个独立的子操作,由不同的CPU同时执行。
- ○操作间并行。一条SQL查询语句可以分解成多个子操作,由多个CPU执行
1.5 分布式查询计划#
在分布式数据库系统中,查询策略优化(主要是数据传输策略,A、B两结点的数据进行连接,是A结点数据传输到B结点或从B到A或先各自进行过滤然后再传输等)和局部处理优化(传统的单结点数据库的查询优化技术)是查询优化的重点。
分布式查询优化以减少传输的次数和数据量作为查询优化的目标。分布式数据库系统中的代价估算模型,除了考虑CPU代价和IO代价外,还要考虑通过网络在结点间传输数据的代价。
1.6 其他的优化#
数据库的查询性能,还取决于其他一些因素,如数据库集群系统中的SD(Share Disk)集群和SN(Share Nothing)集群,不同的架构查询优化技术也不同。
SD集群采用的是共享存储方式,在数据的读写时可能产生读写冲突,所以单表扫描会受到影响;
SN集群采用的是非共享式存储方式,所以在考虑了通信代价后单结点的优化方式依然适用。
二、逻辑查询优化#
逻辑查询优化的主要思路有:
- 子句的局部优化:比如等价谓词重写、WHERE和HAVING条件化简;
- 子句间关联优化:如外连接消除、连接消除、子查询优化、视图重写等都属于子句间的关联优化;
- 局部与整体的优化:比如OR展开为UNION
- 形式变化优化:多个子句存在嵌套,可以消除嵌套
- 语义优化。根据完整性约束、SQL表达的含义等信息对语句进行语义优化。
2.1 查询优化技术的理论基础#
查询优化技术的理论基础是关系代数,优化前和优化后的语义必须等价。
2.2 查询重写规则#
2.2.1 子查询优化#
子查询可以分为:
- 相关子查询。子查询的执行依赖于外层父查询的一些属性值。子查询因依赖于父查询的参数,当父查询的参数改变时,子查询需要根据新参数值重新执行。
- 非相关子查询。子查询的执行不依赖于外层父查询的任何属性值,这样的子查询具有独立性。
子查询转换为Join的好处:
- 子查询不用执行很多次。
- 优化器可以根据统计信息来选择不同的连接方法和不同的连接顺序。
- 子查询中的连接条件、过滤条件分别变成了父查询的连接条件、过滤条件,优化器可以对这些条件进行下推,以提高执行效率。
子查询优化技术的思路:
子查询合并(Subquery Coalescing)。在某些条件下(语义等价:两个查询块产生同样的结果集),多个子查询能够合并成一个子查询(合并后还是子查询,以后可以通过其他技术消除子查询)。这样可以把多次表扫描、多次连接减少为单次表扫描和单次连接,如:
1
2
3SELECT * FROM A WHERE A.id IN (SELECT id FROM B WHERE B.value = 'x')
UNION
SELECT * FROM A WHERE A.id IN (SELECT id FROM B WHERE .value = 'y');可以合并为:
1
SELECT * FROM A WHERE A.id IN (SELECT id FROM B WHERE B.value IN ('x', 'y'));
子查询展开(Subquery Unnesting)。把一些子查询置于外层的父查询中,作为连接关系与外层父查询并列,其实质是把某些子查询重写为等价的多表连接操作。
1
SELECT * FROM t1, (SELECT * FROM t2 where t2.a2>10) v WHERE t1.a1<10 and v.a2 < 20;
可以重写为:
1
SELECT * FROM t1, t2 WHERE t1.a1<10 and t2.a2>10 and t2.a2 < 20;
如果子查询中出现了聚集、GROUPBY、DISTINCT子句,则子查询只能单独求解,不可以上拉到上层。
如果子查询只是一个简单格式(SPJ格式)的查询语句,则可以上拉到上层,这样往往能提高查询效率。
2.2.2 视图重写#
视图重写后的SQL多被作为子查询进行进一步优化。所有的视图都可以被子查询替换。
2.2.3 等价谓词重写#
Like规则#
LIKE谓词的重写规则主要是将LIKE谓词转换为等价的等值谓词或范围谓词。
LIKE 'abc%'→LIKE 'abc' OR LIKE 'abc_' OR LIKE 'abc__' ...
BETWEEN-AND规则#
BETWEEN-AND谓词的重写规则主要是将BETWEEN-AND谓词转换为等价的范围谓词。部分引擎可能没有对BETWEEN-AND的范围扫描提供优化,改写为范围谓词后才可以走索引。
BETWEEN 1 AND 10→>= 1 AND <= 10
IN转换为OR规则#
IN谓词等价重写为若干个OR谓词,可以更好地利用索引优化,提高效率
IN (1, 2, 3)→= 1 OR = 2 OR = 3
OR重写并集规则#
将OR条件转换为UNION ALL的形式,可以更好地利用索引优化,提高效率。
WHERE a = 1 OR a = 2→UNION ALL (SELECT * FROM t WHERE a = 1) UNION ALL (SELECT * FROM t WHERE a = 2)
2.2.4 条件化简#
将WHERE、HAVING和ON条件化简的方式通常包括如下几个:
- 把HAVING条件并入WHERE条件。便于统一、集中化解条件子句,节约多次化解时间。但不是任何情况下HAVING条件都可以并入WHERE条件,只有在SQL语句中不存在GROUPBY条件或聚集函数的情况下,才能将HAVING条件与WHERE条件的进行合并。
- 去除表达式中冗余的括号。这样可以减少语法分析时产生的AND和OR树的层次。
- 常量传递。对不同关系可以使得条件分离后有效实施“选择下推”,从而可以极大地减小中间关系的规模。如col_1=col_2ANDcol_2=3就可以化简为col_1=3 AND col_2=3。
- 消除死码。化简条件,将不必要的条件去除。如 WHERE(0>1 AND s1=5)
- 表达式计算。对可以求解的表达式进行计算,得出结果。如WHERE col_1=1+2变换为WHERE col_1=3。
- 等式变换。化简条件(如反转关系操作符的操作数的顺序),从而改变某些表的访问路径。如-a=3可化简为a=-3。这样的好处是如果a上有索引,则可以利用索引扫描来加快访问。
- 不等式变换。化简条件,将不必要的重复条件去除。如a>10 AND b=6 AND a>2可化简为 b=6 AND a>10。
- 布尔表达式变换。在上面的内容中,涉及了一些布尔表达式参与的变换(如上一条中的示例是AND的表达式)。布尔表达式还有如下规则指导化简。
- 谓词传递闭包。一些比较操作符,如<、>等,具有传递性,可以起到化简表达式的作用。如由a>b AND b>2可以推导出a>bAND b>2AND a>2,a>2是一个隐含条件。
2.2.5 外连接消除#
查询重写的一项技术就是把外连接转换为内连接,转换的意义(对优化的意义)如下:
- 查询优化器在处理外连接操作时所需执行的操作和时间多于内连接。
- 优化器在选择表连接顺序时,可以有更多更灵活的选择,从而可以选择更好的表连接顺序,加快查询执行的速度。
- 表的一些连接算法(如块嵌套连接和索引循环连接等)将规模小的或筛选条件最严格的表作为“外表”(放在连接顺序的最前面,是多层循环体的外循环层),可以减少不必要的IO开销,极大地加快算法执行的速度。
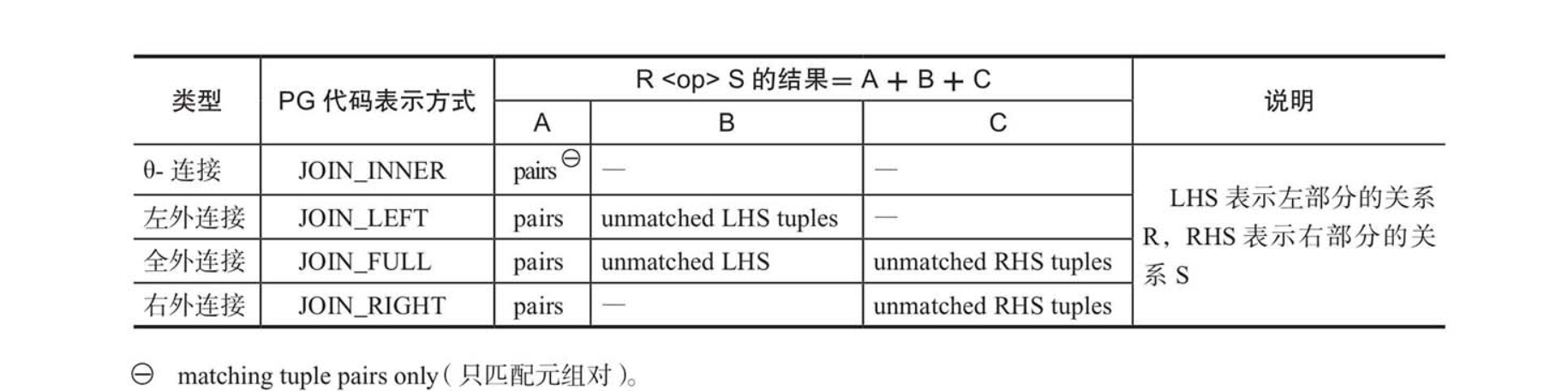
左外连接向内连接转换#
左外连接比θ-连接多了B部分。假设一个左外连接执行之后,其结果等同于内连接,即B部分不存在,则这种情况下,左外连接就可以向内连接转换。
严格的条件是: 右面关系中对应的条件,保证最后的结果集中不会出现B部分这样特殊的元组(这样的条件称为“reject-NULL条件”)。语义满足左外连接,但实际结果因两个表中数据的有特点(满足reject-NULL条件)。形式上看是外连接,其实质成为一种褪化的内连接。
全外连接向左外连接转换#
先看全外连接和左外连接,相同之处在于都具有A、B部分,不同之处是全外连接比左外连接多了C部分。
假设一个全外连接执行之后,其结果等同于左外连接,即C部分不存在,则这种情况下,全外连接就可以向左外连接转换。
全外连接如果能同时向左外连接和右外连接转换,则意味着全外连接能转换为内连接。其条件是:左面和右面关系中对应的条件,均能满足reject-NULL条件。
右外连接向内连接转换#
因右外连接对称等同左外连接,所以通常都是把右外连接转换为左外连接,然后再向内连接转换。右外连接向左外连接转换,通常是发生在语法分析阶段。
外连接消除条件#
外连接可转换为内连接的条件:WHERE子句中与内表相关的条件满足“空值拒绝”(reject-NULL条件):
- 条件可以保证从结果中排除外连接右侧(右表)生成的值为NULL的行,所以能使该查询在语义上等效于内连接。
- 外连接的提供空值的一侧(可能是左侧的外表也可能是右侧的内表)为另一侧的每行只返回一行。如果该条件为真,则不存在提供空值的行,并且外连接等价于内连接。
1 | create table X (X_num int, X_name varchar(10)); |
2.2.6 嵌套连接消除#
如果连接表达式只包括内连接,括号可以去掉,这意味着表之间的次序可以交换,这是关系代数中连接的交换律的应用。
如果连接表达式包括外连接,括号不可以去掉,意味着表之间的次序只能按照原语义进行,至多能执行的就是外连接向内连接转换的优化。
2.2.7 连接消除#
情况一:主外键关系的表进行的连接,可消除主键表,这不会影响对外键表的查珣#
如果对于关系A、B存在A参照B(连接条件上是主外键关系,A依赖于B),且二者之间的连接条件是等值连接(A join B,连接条件是A.a1=B.b1),则经过连接消除,二表连接变为单表扫描(A.a1 IS NOT NULL),这样能有效提高SQL的执行效率。
情况二:唯一键作为连接条件,三表内连接可以去掉中间表(中间表的列只作为连接条件)。#
2.2.8 语义优化#
语义优化常见的方式如下:
- 连接消除(Join Elimination)。对一些连接操作先不必评估代价,根据已知信息(主要依据完整性约束等,但不全是依据完整性约束)能推知结果或得到一个简化的操作。例如,利用A、B两个基表做自然连接,创建一个视图V,如果在视图V上执行查询只涉及其中一个基表的信息,则对视图的查询完全可以转化为对某个基表的查询。
- 连接引入(Join Introduction)。增加连接有助于原关系变小或原关系的选择率降低。
- 谓词引入(Predicate Introduction)。根据完整性约束等信息引入新谓词,如引入基于索引的列,可能使得查询更快。
- 检测空回答集(Detecting the Empty Answer Set)。查询语句中的谓词与约束相悖,可以推知条件结果为FALSE,
- 排序优化(Order Optimizer)。ORDERBY操作通常由索引或排序(sort)完成;如果能够利用索引,则排序操作可省略。
- 唯一性使用(Exploiting Uniqueness)。利用唯一性、索引等特点,检查是否存在不必要的DISTINCT操作
2.2.9 针对非SPJ的优化#
GROUP BY优化#
- 分组操作下移。GROUPBY操作可能较大幅度地减少关系元组的个数,如果能够对某个关系先进行分组操作,然后再进行表之间的连接,很可能提高连接效率。
- 分组操作上移。如果连接操作能够过滤掉大部分元组,则先进行连接后进行GROUPBY操作,可能提高分组操作的效率。
ORDER BY 优化#
- 排序消除(Order By Elimination,OBYE)。优化器在生成执行计划前,将语句中没有必要的排序操作消除(如利用索引),避免在执行计划中出现排序操作或由排序导致的操作(如在索引列上排序,可以利用索引消除排序操作)。
- 排序下推(Sort push down)。把排序操作尽量下推到基表中,有序的基表进行连接后的结果符合排序的语义,这样能避免在最终的大的连接结果集上执行排序操作。
DISTINCT优化#
- DISTINCT消除(Distinct Elimination)。如果表中存在主键、唯一约束、索引等,则可以消除查询语句中的DISTINCT。
- DISTINCT推入(Distinct Push Down)。生成含DISTINCT的反半连接查询执行计划时,先进行反半连接再进行DISTICT操作,也许先执行DISTICT操作再执行反半连接更优,这是利用连接语义上确保唯一功能特性进行DISTINCT的优化。
- DISTINCT迁移(Distinct Placement)。对连接操作的结果执行DISTINCT,可能把DISTINCT移到一个子查询中优先进行
2.3 启发式规则在逻辑优化阶段的应用#
一定能带来优化效果的,主要包括:
- 优先做选择和投影(连接条件在查询树上下推)。
- 子查询的消除。
- 嵌套连接的消除。
- 外连接的消除。
- 连接的消除。
- 使用等价谓词重写对条件化简。
- 语义优化。
- 剪掉冗余操作(一些剪枝优化技术)、最小化查询块。
变换未必会带来性能的提高,需根据代价选择,主要包括:
- 分组的合并。
- 借用索引优化分组、排序、DISTINCT等操作。
- 对视图的查询变为基于表的查询。
- 连接条件的下推。
- 分组的下推。
- 连接提取公共表达式。
- 谓词的上拉。
- 用连接取代集合操作。
- 用UNIONALL取代OR操作。